
Giới thiệu về Dimensinality Reduction
Trong thời đại dữ liệu lớn ngày nay, chúng ta thường phải đối mặt với các tập dữ liệu có hàng trăm, thậm chí hàng nghìn chiều (features).Một ảnh 28×28 pixel như trong bộ dữ liệu MNIST có thể tương đương với 784 đặc trưng. Một vector embedding sinh ra từ mô hình ngôn ngữ hiện đại có thể có 768, 1024 hoặc thậm chí nhiều hơn. Tuy nhiên, con người chỉ có thể trực quan hóa trong không gian 2 hoặc 3 chiều. Điều này khiến việc quan sát, phân tích và hiểu cấu trúc của dữ liệu cao chiều trở thành một thách thức lớn.
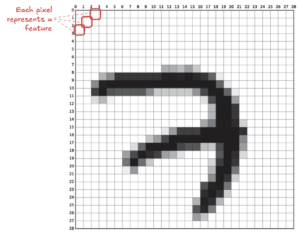
May mắn thay, trong nhiều bài toán thực tế, dữ liệu cao chiều không thực sự phức tạp như số lượng feature mà ta nhìn thấy. Rất nhiều chiều trong đó có thể dư thừa, nhiễu hoặc mang thông tin trùng lặp. Điều này mở ra khả năng giảm chiều dữ liệu mà không làm mất đi bản chất quan trọng của nó.
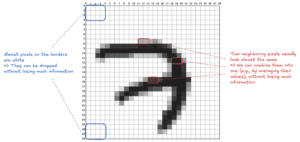
Lấy ví dụ với bộ dữ liệu chữ số viết tay MNIST. Mỗi ảnh có 784 pixel, tương đương 784 chiều. Tuy nhiên, các pixel ở góc ảnh thường gần như luôn có giá trị bằng 0 (màu trắng), nên ta có thể loại bỏ những pixel này mà gần như không ảnh hưởng đến kết quả. Ngoài ra, các pixel nằm cạnh nhau thường có giá trị tương đồng do tính liên tục của hình ảnh. Thay vì giữ nguyên từng pixel riêng lẻ, ta có thể gộp các vùng lân cận lại – ví dụ lấy trung bình của hai hoặc nhiều pixel để tạo thành một đặc trưng mới. Cách làm này giúp giảm số chiều trong khi vẫn bảo toàn cấu trúc tổng thể của hình ảnh.
Từ nhu cầu giảm chiều nhưng vẫn bảo toàn cấu trúc quan trọng của dữ liệu, các phương pháp thu giảm số chiều (dimensionality reduction) có thể được chia thành hai hướng tiếp cận chính: Projection, dựa trên phép chiếu tuyến tính, và Manifold Learning, tập trung vào việc khám phá cấu trúc hình học phi tuyến tiềm ẩn của dữ liệu.
Phương pháp Projection
Phương pháp đầu tiên và phổ biến nhất trong giảm chiều là Projection. Ý tưởng cốt lõi của nhóm này rất trực quan: tìm một phép chiếu từ không gian nhiều chiều xuống không gian ít chiều hơn sao cho giữ lại được nhiều thông tin nhất có thể.
Hãy tưởng tượng ta có một tập dữ liệu trong không gian 3 chiều (x,y,z), nhưng quan sát kỹ thì các điểm dữ liệu thực tế lại nằm gần như trên cùng một mặt phẳng 2 chiều. Khi đó, ta có thể chiếu (project) vuông góc từng điểm dữ liệu xuống mặt phẳng này. Kết quả thu được là một tập dữ liệu mới chỉ còn 2 chiều, với mỗi điểm được biểu diễn bằng hai tọa độ mới
, chính là tọa độ của các điểm chiếu trên mặt phẳng mới. Như vậy, ta đã giảm số chiều từ 3 xuống 2 mà vẫn giữ lại được phần lớn cấu trúc quan trọng của dữ liệu.
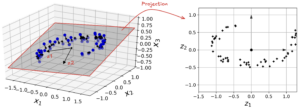
Tất cả các điểm màu xanh dương nằm gần một mặt phẳng 2D màu xám. Chiếu chúng lên mặt phẳng này sẽ giảm dữ liệu từ 3D về 2D.
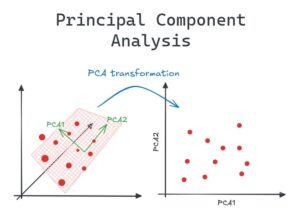 Principal Component Analysis (PCA) là thuật toán tiêu biểu trong các phương pháp projection, bằng cách tìm ra các trục tọa độ mới sao cho lượng thông tin gốc khi chiếu lên các trục này được bảo toàn nhiều nhất
Principal Component Analysis (PCA) là thuật toán tiêu biểu trong các phương pháp projection, bằng cách tìm ra các trục tọa độ mới sao cho lượng thông tin gốc khi chiếu lên các trục này được bảo toàn nhiều nhất
Tuy các phương pháp projection dù hiệu quả và dễ triển khai, lại có một giới hạn quan trọng: chúng giả định rằng cấu trúc của dữ liệu có thể được mô tả tốt bằng một phép biến đổi tuyến tính. Trong thực tế, giả định này không phải lúc nào cũng đúng.
Hãy tưởng tượng dữ liệu của chúng ta không nằm trên một mặt phẳng, mà uốn cong như một dải ruy băng hình chữ S trong không gian 3 chiều. Nếu ta áp dụng một phép chiếu tuyến tính xuống mặt phẳng 2 chiều, cấu trúc cong này sẽ bị “ép phẳng”, khiến các layer của mặt cong này bị chồng lấn (overlap) lên nhau. Khi đó, cấu trúc lân cận ban đầu bị phá vỡ, làm mất đi thông tin quan trọng về hình dạng thực sự của dữ liệu.
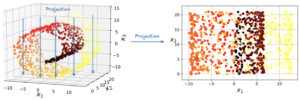 Dữ liệu tạo thành một bề mặt 2D cuộn tròn bên trong không gian 3D. Phương pháp Projection khiến các lớp của bề mặt chồng lên nhau
Dữ liệu tạo thành một bề mặt 2D cuộn tròn bên trong không gian 3D. Phương pháp Projection khiến các lớp của bề mặt chồng lên nhau
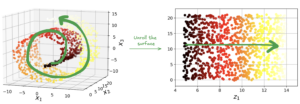
Trong khi đó, điều chúng ta thật sự muốn là trải phẳng mặt cong này, để lộ cấu trúc 2D ban đầu của nó.
 Phương pháp Projection không phải lúc nào cũng bảo toàn cấu trúc cơ bản của dữ liệu
Phương pháp Projection không phải lúc nào cũng bảo toàn cấu trúc cơ bản của dữ liệu
Chính vì hạn chế này, các phương pháp Manifold Learning được đề xuất nhằm khai thác cấu trúc hình học phi tuyến tiềm ẩn của dữ liệu, thay vì chỉ dựa vào các phép chiếu tuyến tính.
Phương pháp Manifold Learning
Trước khi nói về manifold learning, ta cần hiểu manifold là gì. Một cách dễ hiểu, manifold là một cấu trúc có thể cong tồn tại trong không gian nhiều chiều. Thoạt nhìn toàn bộ thì nó có vẻ phức tạp, nhưng nếu chỉ nhìn ở một vùng nhỏ thì nó gần như phẳng.
Hãy cùng xem qua một số ví dụ về manifold như sau:
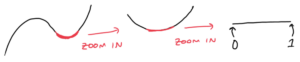
Đường cong này là một manifold 1 chiều: nó tồn tại trong không gian 2 chiều (hoặc 3 chiều), nhưng khi phóng to, nó trông giống như một đường thẳng (1 chiều).
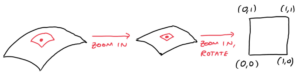
Bề mặt cong này là một manifold 2 chiều: nó tồn tại trong không gian 3 chiều (hoặc hơn), nhưng khi phóng to một phần nhỏ hoặc làm phẳng nó ra, nó trông giống như một mặt phẳng 2D.
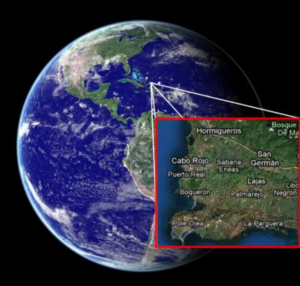 Một ví dụ thực tiễn hơn: bề mặt Trái Đất cũng là một manifold 2 chiều. Khi nhìn tổng thể từ ngoài vũ trụ Trái Đất sẽ có dạng hình cầu, nhưng nếu đứng ở một khu vực nhỏ thì mặt đất sẽ gần như phẳng
Một ví dụ thực tiễn hơn: bề mặt Trái Đất cũng là một manifold 2 chiều. Khi nhìn tổng thể từ ngoài vũ trụ Trái Đất sẽ có dạng hình cầu, nhưng nếu đứng ở một khu vực nhỏ thì mặt đất sẽ gần như phẳng
Trong dữ liệu cũng vậy, mặc dù chúng có thể được biểu diễn trong không gian có số chiều rất cao, nhưng thực chất nó chỉ nằm trên một manifold có số chiều thấp hơn nhiều. Nói cách khác, thực chất dữ liệu không hề phức tạp như chúng ta thấy, chúng chỉ đang nằm trên một “bề mặt” có số chiều thấp hơn bên trong không gian cao chiều đó. Đây chính là manifold assumption, giả định quan trọng xây dựng nên phương pháp manifold learning.
Manifold Learning cố gắng tìm ra cấu trúc ẩn này và biểu diễn lại dữ liệu trong không gian thấp chiều sao cho hình học tự nhiên của manifold được bảo toàn, đặc biệt là quan hệ giữa các điểm lân cận.
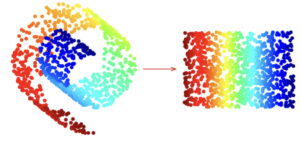 Ví dụ: Tuy dữ liệu tồn tại trong không gian 3 chiều, nhưng thực chất chúng chỉ đang nằm trên 1 đường cong (manifold 2 chiều). Các phương pháp Manifold Learning sẽ cố gắng tìm ra cấu trúc này và “trải phẳng” ra trong không gian 2 chiều, trong khi vẫn bảo toàn được cấu trúc thật sự của dữ liệu gốc
Ví dụ: Tuy dữ liệu tồn tại trong không gian 3 chiều, nhưng thực chất chúng chỉ đang nằm trên 1 đường cong (manifold 2 chiều). Các phương pháp Manifold Learning sẽ cố gắng tìm ra cấu trúc này và “trải phẳng” ra trong không gian 2 chiều, trong khi vẫn bảo toàn được cấu trúc thật sự của dữ liệu gốc
Lời kết
Trong bài viết này, chúng ta bắt đầu từ bài toán giảm chiều dữ liệu và phân biệt hai hướng tiếp cận chính: Projection và Manifold Learning. Trong khi các phương pháp projection như PCA cố gắng tìm các chiều dữ liệu mới giúp bảo toàn thông tin được nhiều nhất, thì manifold learning lại dựa trên giả định rằng dữ liệu cao chiều thực chất nằm trên một manifold có chiều thấp hơn và tìm cách học được cấu trúc của manifold này. Điều đó khiến cho các phương pháp Manifold Learning sẽ phù hợp hơn với những loại dữ liệu có cấu trúc phi tuyến phức tạp — nơi quan hệ giữa các điểm không thể được mô tả tốt bằng một phép chiếu tuyến tính đơn giản.
Trong bài viết sau, chúng ta sẽ cùng nhau tìm hiểu về t-Distributed Stochastic Neighbor Embedding (t-SNE) — một thuật toán giảm chiều mạnh mẽ dựa trên phương pháp Manifold Learning — cùng với tiền thân của nó là Stochastic Neighbor Embedding (SNE). Chúng ta sẽ lần lượt đi từ ý tưởng ban đầu của SNE, những hạn chế của nó, cho đến cách t-SNE được cải tiến để khắc phục các vấn đề đó và trở thành công cụ trực quan hóa dữ liệu phổ biến hiện nay.
References
- Aurelien Géron, Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems, 2nd Edition, O’Reilly Media, 2019
- Manifolds — Part 1, Existence Proof Blog, 03 Nov 2017
- Parallel Implementation of nonlinear dimensionality reduction methods applied in object segmentation using CUDA in GPU, ResearchGate