I. Nghịch lý của trực giác cũ:
1. Bias-variance tradeoff có phù hợp với các mô hình deep learning?
Trong nhiều năm, người ta tin vào một nguyên tắc khá đơn giản: mô hình càng phức tạp thì càng dễ học quá mức (overfit).
Hãy tưởng tượng bạn đang luyện thi. Nếu bạn học vừa đủ để hiểu bản chất vấn đề, bạn sẽ làm bài ổn định. Nhưng nếu bạn cố ghi nhớ từng chi tiết nhỏ, từng câu hỏi cụ thể, bạn có thể làm rất tốt đề đã học – nhưng lại dễ “toang” khi gặp đề mới.
Trong machine learning cũng vậy.
Hình 1 minh họa điều này bằng một đường cong hình chữ U quen thuộc minh họa nguyên tắc bias-variance tradeoff. Theo nguyên tắc này, khi mô hình còn nhỏ, nó không đủ khả năng học hết quy luật của dữ liệu – ta gọi là underfit. Khi tăng kích thước, mô hình học tốt hơn và lỗi giảm xuống. Nhưng nếu tiếp tục tăng kích thước, mô hình bắt đầu “học cả nhiễu”, tức là học luôn những yếu tố ngẫu nhiên không quan trọng. Khi đó lỗi trên dữ liệu mới sẽ tăng lên – đó là overfit.
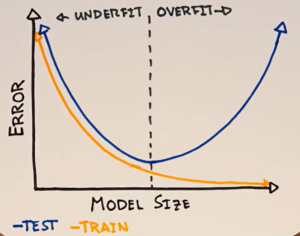
Từ trực giác này, ta sẽ nghĩ rằng nếu mô hình có hàng triệu hay hàng tỷ tham số thì chắc chắn phải overfit rất nặng. Nhưng thực tế lại không như vậy. Các mô hình deep learning khổng lồ vẫn hoạt động rất tốt ngoài đời.
Vậy chuyện gì đang xảy ra?
Ban đầu, nhiều người cho rằng các mô hình lớn thực chất vẫn đang nằm ở vùng overfit của đường cong chữ U. Theo cách nghĩ đó, regularisation chỉ đơn giản giúp “hãm” mô hình lại, kéo nó quay về gần điểm tối ưu của đường cong (Hình 2).
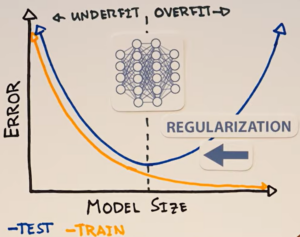
Nghe có vẻ hợp lý, nhưng rồi một thí nghiệm đã làm lung lay niềm tin này.
2. Thí nghiệm Random Labels:
Năm 2016, một đội ở Google Brain đã thực hiện một nghiên cứu để kiểm tra xem regularisation giúp kiểm soát overfit đến mức độ nào.
Họ đã làm một điều khá đơn giản: tráo ngẫu nhiên toàn bộ nhãn của dữ liệu.
Ví dụ: ảnh mèo được gán nhãn “máy bay”, ảnh chó được gán nhãn “tàu hỏa”. Lúc này, giữa ảnh và nhãn không còn bất kỳ quy luật nào.
Nếu regularisation thực sự ngăn mô hình học quá mức, ta sẽ mong mô hình không thể học được tập dữ liệu vô nghĩa này.
Nhưng kết quả lại hoàn toàn ngược lại.
Mô hình vẫn đạt 100% độ chính xác trên tập huấn luyện, dù nhãn bị tráo hoàn toàn. Trong khi đó, lỗi trên tập kiểm tra thì cực kỳ tệ.
Cùng một mô hình và cùng một cách regularisation, khi không tráo nhãn lại thể hiện tốt trên cả tập huấn luyện và tập kiểm tra (Hình 3).
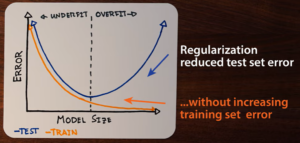
Điều này giải thích rằng regularisation không đơn giản hãm mô hình lại trước khi overfit. Mô hình vẫn đủ mạnh để ghi nhớ hoàn toàn tập huấn luyện, kể cả khi dữ liệu không có quy luật.
Vậy câu hỏi nghìn đô ở đây là: Nếu một mô hình đủ lớn để khớp hoàn hảo (interpolate) toàn bộ tập huấn luyện – tức là có thể “học thuộc” dữ liệu – thì theo trực giác truyền thống, nó sẽ bị overfit. Vậy tại sao trên thực tế, những mô hình như vậy vẫn có thể tổng quát hóa tốt trên dữ liệu mới (khi dữ liệu có cấu trúc/quy luật)? Điều này cho thấy phân tích bias-variance truyền thống đang bỏ sót yếu tố nào?
II. Hiện tượng Double Descent: Sự mở rộng của đường cong bias-variance
1. Double Descent là gì?
Có thể đường cong chữ U quen thuộc kia không sai, nhưng chưa phản ánh được bức tranh tổng thể. Đó là những gì một nghiên cứu đề xuất vào năm 2018, kèm theo đó là một sự mở rộng của đường cong bias-variance (được kiểm chứng trên một mô hình neural network nhỏ) (Hình 4):
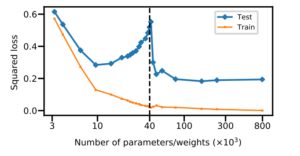
Ta có thể thấy ở mô hình này, khi số tham số tăng đến 40.103 tham số thì mọi thứ diễn ra như những gì ta biết về bias-variance tradeoff. Nhưng khi số tham số tăng nhiều hơn thì độ lỗi trên cả tập huấn luyện và tập test đều có xu hướng giảm. Hiện tượng này đã được đặt tên là “Double Descent”.
Khi hiện tượng Double Descent xuất hiện, đường cong chữ U quen thuộc không còn kết thúc ở phần “overfit” nữa. Thay vào đó, nó tiếp tục kéo dài và tạo thành một nhịp giảm thứ hai.
Ban đầu, khi số tham số còn ít, mô hình chưa đủ khả năng học hết quy luật của dữ liệu. Nó bỏ sót nhiều thông tin quan trọng nên mắc lỗi nhiều – đây là giai đoạn underfit.
Khi số tham số tăng lên, mô hình dần dần học được nhiều quy luật hơn. Lỗi trên tập kiểm tra giảm xuống và đạt mức tốt nhất ở một điểm tối ưu – giống như những gì đường cong chữ U truyền thống mô tả.
Nếu tiếp tục tăng số tham số vượt qua ngưỡng này, mô hình bắt đầu đủ mạnh để khớp hoàn toàn tập huấn luyện. Nó không chỉ học quy luật mà còn học cả nhiễu. Kết quả là lỗi trên tập kiểm tra tăng lên đến đỉnh (interpolation threshold) – đây chính là vùng overfit mà ta đã quen thuộc.
Nhưng điều bất ngờ xảy ra khi ta tiếp tục tăng số tham số thêm nữa. Sau interpolation threshold, hay vì lỗi tiếp tục tăng, ở một mức đủ lớn, lỗi trên tập kiểm tra lại giảm xuống lần thứ hai. Đó chính là phần “descent” thứ hai trong Double Descent.
Điều quan trọng là hiện tượng này không chỉ xuất hiện trong các mô hình nhỏ hay các thí nghiệm lý thuyết. Năm 2019, các nhà nghiên cứu tại Harvard và OpenAI đã thử nghiệm lại trên những kiến trúc deep learning thực tế như CNN, ResNet và Transformer. Kết quả cho thấy Double Descent vẫn xuất hiện rõ ràng trong các mô hình này (Hình 5).
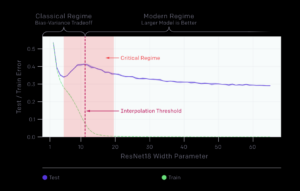
2. Nguyên nhân:
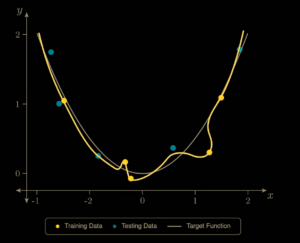
Mặc dù Double Descent đã được quan sát trong nhiều thí nghiệm, nguyên nhân chính xác của hiện tượng này vẫn chưa được hiểu trọn vẹn. Tuy vậy, ta có thể hình dung nó một cách trực giác thông qua một ví dụ quen thuộc trong toán học: bài toán tìm một đa thức dựa vào một các điểm dữ liệu có nhiễu đã cho từ đa thức cần tìm (polynomial curve-fitting).
Hãy tưởng tượng mô hình của ta chỉ vừa đủ tham số để khớp hoàn toàn tập huấn luyện. Khi đó, để đi qua mọi điểm dữ liệu – kể cả những điểm nhiễu – mô hình buộc phải uốn cong rất mạnh. Đường dự đoán trở nên lượn sóng, nhạy cảm với từng dao động nhỏ trong dữ liệu và vì thế kém ổn định. Đây chính là vùng ngay “interpolation threshold”, nơi lỗi trên tập kiểm tra đạt đỉnh (Hình 6)
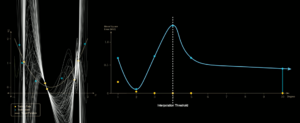
Nói cách khác, ở vùng mô hình cực lớn, vấn đề không còn là “có học hết dữ liệu hay không”, mà là “học theo cách nào”.
Cũng cần lưu ý rằng Double Descent không phủ nhận hoàn toàn bias-variance tradeoff. Với các mô hình nhỏ hoặc nhiều thuật toán học máy truyền thống, đường cong chữ U quen thuộc vẫn là mô tả hợp lý. Hiện tượng Double Descent có thể xuất hiện khi mô hình đủ lớn để có nhiều cách khác nhau khớp hoàn toàn tập huấn luyện.
III. Ý nghĩa với Deep Learning hiện đại:
Từ thí nghiệm tráo nhãn và hiện tượng Double Descent, ta rút ra một điều quan trọng: khả năng ghi nhớ hoàn toàn dữ liệu không tự động đồng nghĩa với việc mô hình sẽ tổng quát kém. Trong các mô hình deep learning lớn, vấn đề không chỉ nằm ở số lượng tham số, mà ở chỗ trong vô số lời giải có thể khớp dữ liệu, quá trình huấn luyện đã tìm đến lời giải nào.
Nói cách khác, khi mô hình đủ lớn, câu hỏi không còn là “có khớp hoàn toàn tập huấn luyện hay không”, mà là “khớp theo cách nào”. Có những lời giải khớp dữ liệu nhưng rất dao động và kém ổn định, nhưng cũng có những lời giải mượt hơn và tổng quát tốt hơn. Chính quá trình tối ưu và các kỹ thuật điều chỉnh mới đóng vai trò định hướng mô hình đến những lời giải tốt.
Điều này cũng thay đổi cách ta nhìn về kích thước mô hình. Trong deep learning hiện đại, mô hình lớn không phải lúc nào cũng là vấn đề. Trái lại, khi vượt qua một ngưỡng nhất định, việc tăng kích thước còn có thể giúp mô hình hoạt động ổn định và tổng quát tốt hơn. Đây là một trong những lý do vì sao xu hướng xây dựng các mô hình ngày càng lớn vẫn tiếp tục trong thực tế.