Giới thiệu tổng quan Hidden Markov Models
Bạn đã bao giờ nhìn vào biểu hiện của một người để đoán xem họ đang nghĩ gì chưa?
Bạn đang chạy trên một con phố ồn ào, tiếng còi xe inh ỏi. Bạn kề điện thoại lên và nói vội: “Hey Siri, đặt báo thức lúc 6 giờ sáng”. Gần như ngay lập tức, Siri phản hồi chính xác. Bạn có bao giờ tự hỏi làm thế nào AI có thể ‘lọc’ và hiểu đúng ý bạn giữa mớ âm thanh hỗn độn đó?
Việc giải mã các tín hiệu chuỗi có chứa nhiễu (noisy sequential data) như trên là một thách thức cốt lõi trong lĩnh vực trí tuệ nhân tạo, đặc biệt đối với hệ thống xử lý ngôn ngữ và âm thanh. Để giải quyết vấn đề này, mô hình Markov ẩn (Hidden Markov Models – HMM) nổi lên như một công cụ nền tảng, cho phép mô hình hóa quá trình phát sinh dữ liệu thông qua hệ thống các trạng thái ẩn và quan sát.
Trong tiến trình phát triển của Học máy (Machine Learning), HMM không chỉ là giải pháp tiên phong cho các bài toán nhận dạng giọng nói, mà còn đóng vai trò là viên gạch nền móng về mặt lý thuyết xác suất. Việc thấu hiểu các cơ chế suy diễn trong HMM là bước đệm học thuật vững chắc để các nhà nghiên cứu tiếp cận và phát triển các mô hình Học sâu (Deep Learning) tiên tiến dành riêng cho phân tích dữ liệu tuần tự (sequence modeling).
Trong cuộc sống, có những thứ chúng ta thấy ngay trước mắt nhưng bản chất cốt lõi tạo ra chúng lại nằm ẩn sâu bên dưới. Tuy nhiên, không phải lúc nào chúng ta cũng có thể quan sát trực tiếp bản chất của một sự vật. Mà thay vào đó, chúng ta thường chỉ thấy được biểu hiện bên ngoài của chúng, giống như việc một bác sĩ nhìn vào các triệu chứng bên ngoài (ho, phát ban, sốt) để đoán xem cơ thể mắc bệnh gì, hay việc một nhà tâm lý học nhìn vào hành vi để hiểu về tâm trạng bên trong đang giấu kín.
Tất cả những tình huống đó đều có một điểm chung: Chúng ta quan sát được “biểu hiện” (Observations), nhưng cái ta thực sự quan tâm lại là “bản chất” (Hidden States) nằm ở phía sau.
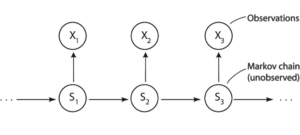
Hidden Markov Model là gì? Tại sao lại gọi là “Hidden”?
Hidden Markov Model (HMM) – hay mô hình Markov ẩn – là một công cụ toán học giúp chúng ta giải quyết bài toán dự đoán một cách khoa học và có hệ thống.
Hãy tưởng tượng bạn có một người bạn tên là An sống ở một thành phố khác. Bạn không hề biết thời tiết ở đó ra sao (đây chính là trạng thái ẩn). Tuy nhiên, mỗi ngày An đều nhắn tin kể cho bạn nghe hôm nay An làm gì: “Đi ăn kem”, “Ở nhà ngủ” hoặc “Đi dạo công viên” (đây chính là quan sát).
Tại sao lại gọi là “Hidden”? Vì bạn không bao giờ nhìn thấy mặt trời hay đám mây ở chỗ An. Bạn chỉ đứng từ xa, nhìn qua những mẩu tin nhắn để suy luận ngược lại: “À, hôm nay An đi ăn kem chắc là trời nắng rồi!” HMM chính là bộ não giúp máy tính thực hiện các suy luận logic đó bằng những con số xác suất cụ thể thay vì chỉ dựa vào cảm tính.
Cấu trúc của một Hidden Markov Model
Để tìm hiểu cấu trúc của một HMM, ta cùng xét lại ví dụ về bạn An ở đầu bài viết. Bạn không biết thời tiết ở chỗ bạn An ra sao (nắng/ mưa/ có mây), nhưng giả sử bạn biết được tâm trạng của bạn An vào ngày hôm đó (vui/ buồn).
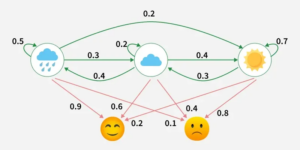
Nhìn vào hình trên, ta sẽ thấy được có 2 thành phần chính: các mũi tên màu xanh chỉ từ thời tiết này sang thời tiết khác và các mũi tên màu đỏ chỉ từ thời tiết sang tâm trạng. Khi đó, thời tiết là các trạng thái ẩn, còn tâm trạng là các quan sát.
- Các mũi tên màu xanh gắn liền với các con số chỉ những thay đổi về thời tiết. Trong hình, ta thấy từ trời mưa sang trời mây là 0.3, nghĩa là chỉ có 30% khả năng ngày mai trời mây nếu hôm nay trời mưa. Vậy từ các con số trên, ta sẽ có được một ma trận các xác suất, và trong Hidden Markov Model, ma trận này được gọi là ma trận chuyển trạng thái.

- Còn với các mũi tên màu đỏ, tương tự như ở trên, ta cũng lập được một ma trận xác suất được gọi là ma trận xác suất biểu hiện. Ý nghĩa của các con số này chính là từ mỗi trạng thái ẩn, ta có thể suy ra được khả năng các quan sát sẽ xảy ra. Ví dụ, nếu trạng thái ẩn là trời mưa, thì xác suất bạn An vui là 90% và bạn An buồn là 10%.
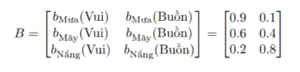
- Hidden Markov Model còn một thành phần nữa chính là giá trị xác suất khởi tạo, chính là xác suất xảy ra các trạng thái ẩn lúc ban đầu. Trong ví dụ này, vì trong hình không đề cập nên thông thường xác suất này sẽ được chia đều cho 3 trạng thái trong hình: π = [1/3, 1/3, 1/3]
Thông qua ví dụ trên, ta có thể rút ra được một Hidden Markov Model sẽ có 3 thành phần chính:
- A – Ma trận chuyển trạng thái: Là xác suất hệ thống nhảy từ trạng thái ẩn này sang trạng thái ẩn khác.
- B – Ma trận xác suất biểu hiện: Là xác suất từ một trạng thái ẩn này xảy ra các quan sát.
- π – Xác suất khởi tạo: Giá trị này cho biết xác suất trạng thái nào xảy ra lúc đầu.
Đến đây, chúng ta đã có trong tay đầy đủ “bộ khung” của một Hidden Markov Model với các ma trận xác suất A, B và π. Chúng ta biết được quy luật thời tiết nhảy từ nắng sang mưa ra sao, và biết luôn cả việc khi trời mưa thì khả năng bạn An buồn (☹️) cao đến mức nào.
Thế nhưng, có một câu hỏi lớn xuất hiện: Nếu bạn nhìn thấy một chuỗi biểu hiện của An trong 3 ngày liên tiếp là ☹️ -> 😃 -> 😃, thì chuỗi thời tiết nào là hợp lý nhất đã xảy ra ở chỗ bạn ấy?
Có hàng chục, hàng trăm kịch bản có thể chạy trong đầu bạn:
- Kịch bản 1: Mưa -> Nắng -> Nắng
- Kịch bản 2: Mưa -> Nhiều mây -> Nắng
- Kịch bản 3: Nhiều mây -> Nhiều mây -> Nắng
- … và còn nhiều nữa.
Làm sao máy tính có thể quét qua tất cả các khả năng này để tìm ra một kịch bản có xác suất cao nhất mà không bị quá tải bởi khối lượng tính toán khổng lồ? Đó chính là lúc chúng ta cần đến thuật toán Viterbi – thuật toán giúp chúng ta giải mã các ma trận xác suất này một cách thông minh và nhanh gọn.
Hãy cùng nhau khám phá thuật toán này và cách nó ứng dụng nguyên lý quy hoạch động (Dynamic Programming) để tìm ra đáp án có khả năng xảy ra cao nhất trong bài viết tiếp theo nhé!
# Reference: